S3
This page provides information for connecting your application to your Amazon S3 bucket and using queries to manage its content.
This datasource can also be used to connect to any S3-compatible object storage provider such as Upcloud, Digital Ocean Spaces, Wasabi, DreamObjects, and MinIO.
Connect S3
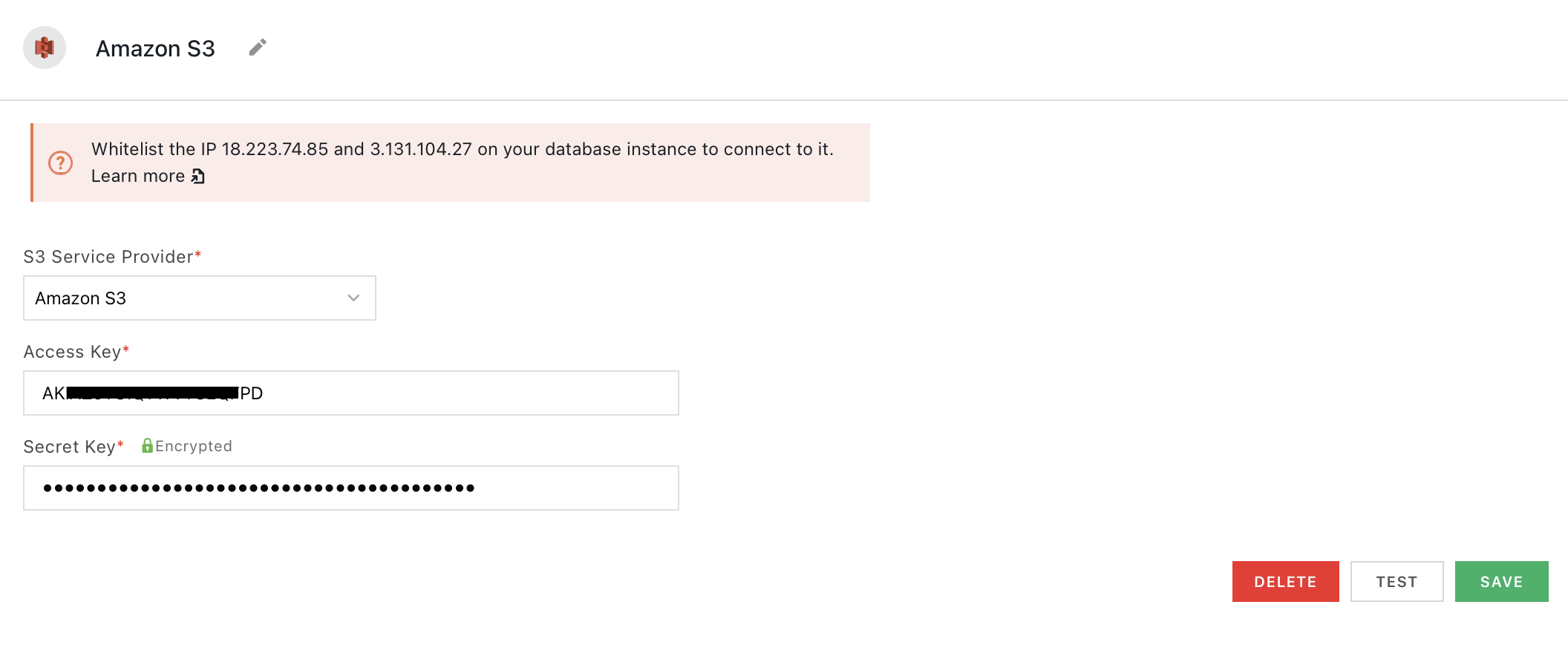
If you are a cloud user, you must whitelist the IP address of the Appsmith deployment 18.223.74.85 and 3.131.104.27 on your S3 instance before connecting to the bucket. For more information about whitelisting on Amazon, see Managing access based on specific IP addresses.
Connection parameters
The following section is a reference guide that provides a complete description of all the parameters to connect to an S3 bucket.
S3 service provider
- Amazon S3
- Upcloud
- Digital Ocean spaces
- Wasabi
- DreamObjects
- MinIO
- Other
Access key
Secret key
Endpoint URL
Region
Identifies which regional data center to connect to. This field appears when S3 service provider is MinIO or Other.
If the configuration is correct but the credentials do not have the required permission, the test operation fails.
Create queries
The following section is a reference guide that provides a complete description of all the read and write operation commands with their parameters to create S3 queries.
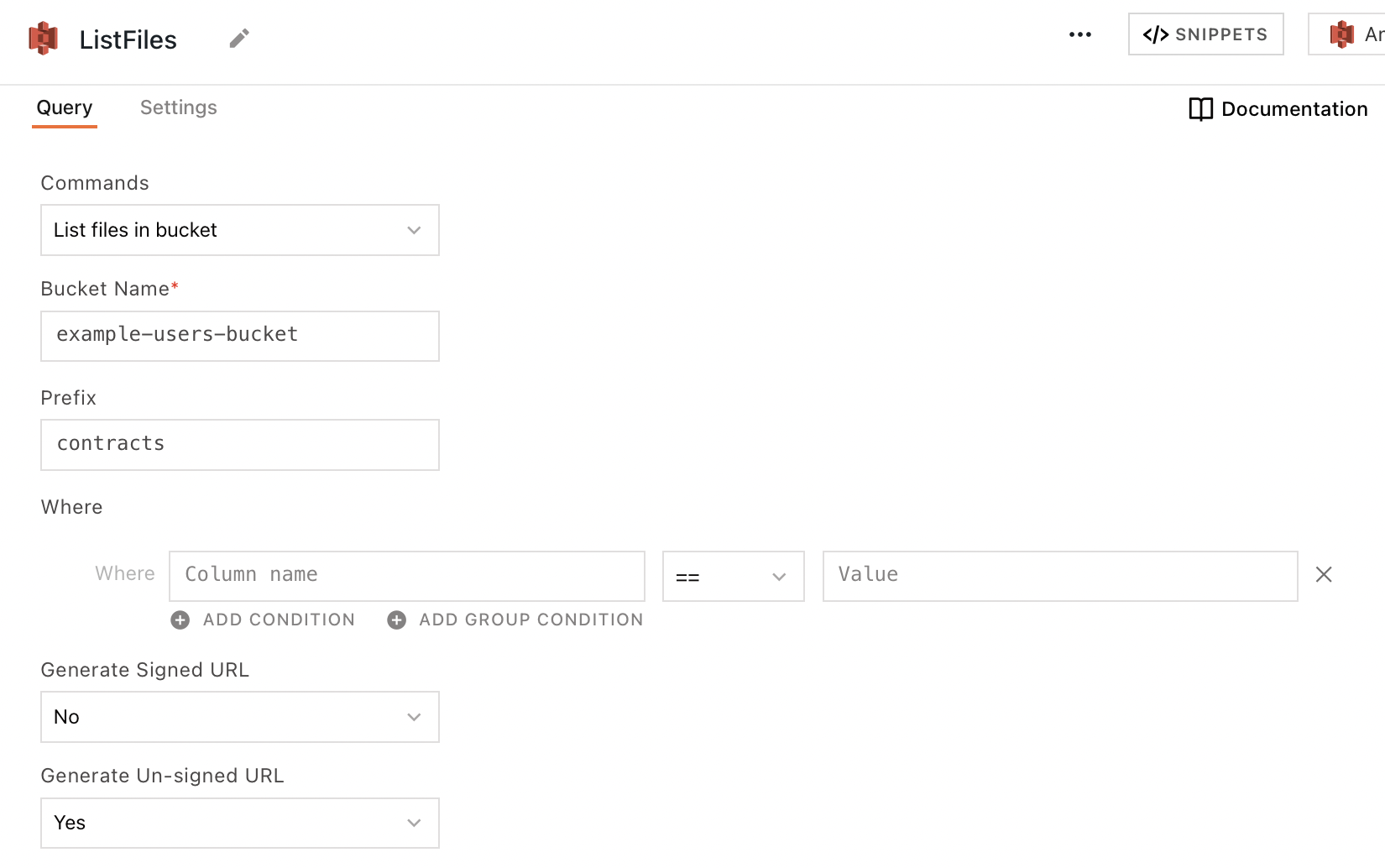
List files in bucket
This command returns an array of objects representing items that are contained within the bucket, each including at least a fileName property. The following section lists all the fields available for the List files in a bucket command.
Bucket name
The name of the S3 bucket to query.
Prefix
The directory path of the files you'd like to query.
For example, in sample/path/example.png, the Prefix is sample/path. Using the prefix sample/path with no filtering returns all files in the sample/path directory.
Where
These fields are used to create logic expressions that filter query results based on column values. Available comparison operators are ==, !=, in, and not in.
Generate signed URL
Requests an authenticated, user-accessible URL for each file in the response. Users may follow the link in their browser to see the content of the file. The URL expires after the amount of time specified in Expiry duration of signed URL.
Expiry duration of signed URL
The length of time in minutes that the returned Signed URL is valid. Accepts number values up to 10080 minutes (7 days).
Generate unsigned URL
Requests the plain URL for each file in the query response. This URL does not expire, but it can't be used to access the resource directly, only via API.
Sort by
Orders the query results in ascending or descending order based on a given column's value.
Pagination limit
Limits the number of results that can be returned in a single response. Expects an integer.
Pagination offset
Skips a given number of files before returning the further results. Expects an integer.
Create a new file
This command creates a new object in the S3 bucket. If a file by the same name or path already exists within the bucket, the old file is overwritten by the new one. The following section lists all the fields available for the Create a new file command.
Bucket name
The name of the S3 bucket to query.
File path
The name under which to save the file. Be sure to include directories as prefixes to the filename if necessary.
File data type
- Base64: Sends data from the Content field encoded in Base64 format.
- Text: Sends data from the Content field as plain text.
Expiry duration of signed URL
The length of time in minutes that the returned Signed URL is valid. Accepts number values up to 10080 minutes (7 days).
Content
The file data to be sent to the bucket. Expects a file object. You can use widgets such as a Filepicker or a Camera to upload files to S3. For guides on this subject, see Upload or Download Files to and from S3 or Upload Images to and from S3.
Create multiple new files
This command creates a batch of new objects in the S3 bucket. If a file by the same name/path already exists within the bucket, the old file is overwritten by the new one. The following section lists all the fields available for the Create multiple new files command.
Bucket name
The name of the S3 bucket to query.
Common file path
The prefix that is prepended to each of the new objects' file path as directories.
File data type
- Base64: Sends data from the Content field encoded in Base64 format.
- Text: Sends data from the Content field as plain text.
Expiry duration of signed URL
The length of time in minutes that the returned Signed URL is valid. Accepts number values up to 10080 minutes (7 days).
Content
The file data to be sent to the bucket. Expects an array of file objects. You can use widgets such as a Filepicker to upload files to S3. For a guide on this subject, see Upload Files to S3 and Download Files.
Read file
This command returns the data from a given file in your S3 bucket. By default, the raw content of the file is returned on the fileData property of the response. The following section lists all the fields available for the Read file command.
Bucket name
The name of the S3 bucket to query.
File path
The path to the file in your S3 bucket.
Base64 Encode File
- Yes: Incoming file data is encoded into Base64 format before it is returned.
- No: Incoming file data is returned as sent with no additional encoding.
If your fileData content is in Base64 format and needs to be decoded, use the JavaScript atob() method.
Delete file
This command deletes a given file from your S3 bucket. The following section lists all the fields available for the Delete file command.
Bucket name
The name of the S3 bucket to query.
File path
The path to the file in your S3 bucket.
Delete multiple files
This command deletes a batch of files from your S3 bucket. The following section lists all the fields available for the Delete multiple files command.
Bucket name
The name of the S3 bucket to query.
List of Files
Expects a JSON array of file paths to be deleted from the S3 bucket.
Troubleshooting
If you are experiencing difficulties, you can refer to the Datasource troubleshooting guide or contact the support team using the chat widget at the bottom right of this page.
See also
- Upload Files to S3 - Learn how to upload files to an S3 bucket using built-in integration and API configurations.
- Display and Lookup Data in List - Learn how to display query results in a List and enable users to look up data efficiently.
- Search and Filter Table Data - Guide on adding search and filter functionality to Tables for better data navigation.